

科学家之一。
-
 IEEEImage Super-Resolution Using Deep Convolutional Networks
IEEEImage Super-Resolution Using Deep Convolutional Networks时间:2015年 | 作者:Chao Dong; Chen Change Loy; Kaiming He; Xiaoou Tang
We propose a deep learning method for single image super-resolution (SR). Our method directly learns an end-to-end mapping between the low/high-resolution images. The mapping is represented as a deep convolutional neural network (CNN) that takes the low-resolution image as the input and outputs the high-resolution one. We further show that traditional sparse-coding-based SR methods can also be viewed as a deep convolutional network. But unlike traditional methods that handle each component separately, our method jointly optimizes all layers. Our deep CNN has a lightweight structure, yet demonstrates state-of-the-art restoration quality, and achieves fast speed for practical on-line usage. We explore different network structures and parameter settings to achieve trade-offs between performance and speed. Moreover, we extend our network to cope with three color channels simultaneously, and show better overall reconstruction quality.
了解更多 -
 IEEESingle Image Haze Removal Using Dark Channel Prior
IEEESingle Image Haze Removal Using Dark Channel Prior时间:2010年 | 作者:Kaiming He; Jian Sun; Xiaoou Tang
In this paper, we propose a simple but effective image prior - dark channel prior to remove haze from a single input image. The dark channel prior is a kind of statistics of the haze-free outdoor images. It is based on a key observation - most local patches in haze-free outdoor images contain some pixels which have very low intensities in at least one color channel. Using this prior with the haze imaging model, we can directly estimate the thickness of the haze and recover a high quality haze-free image. Results on a variety of outdoor haze images demonstrate the power of the proposed prior. Moreover, a high quality depth map can also be obtained as a by-product of haze removal.
了解更多 -
 ICCVDeep Learning Face Attributes in the Wild
ICCVDeep Learning Face Attributes in the Wild时间:2015年 | 作者:Ziwei Liu, Ping Luo, Xiaogang Wang, Xiaoou Tang
Predicting face attributes in the wild is challenging due to complex face variations. We propose a novel deep learning framework for attribute prediction in the wild. It cascades two CNNs, LNet and ANet, which are finetuned jointly with attribute tags, but pre-trained differently. LNet is pre-trained by massive general object categories for face localization, while ANet is pre-trained by massive face identities for attribute prediction. This framework not only outperforms the state-of-the-art with a large margin, but also reveals valuable facts on learning face representation. (1) It shows how the performances of face localization (LNet) and attribute prediction (ANet) can be improved by different pre-training strategies. (2) It reveals that although the filters of LNet are fine-tuned only with imagelevel attribute tags, their response maps over entire images have strong indication of face locations. This fact enables training LNet for face localization with only image-level annotations, but without face bounding boxes or landmarks, which are required by all attribute recognition works. (3) It also demonstrates that the high-level hidden neurons of ANet automatically discover semantic concepts after pretraining with massive face identities, and such concepts are significantly enriched after fine-tuning with attribute tags. Each attribute can be well explained with a sparse linear combination of these concepts.
了解更多 -
 IEEEGuided Image Filtering
IEEEGuided Image Filtering时间:2012年 | 作者:Kaiming He; Jian Sun; Xiaoou Tang
"In this paper, we propose a novel type of explicit image filter - guided filter. Derived from a local linear model, the guided filter generates the filtering output by considering the content of a guidance image, which can be the input image itself or another different image. The guided filter can perform as an edge-preserving smoothing operator like the popular bilateral filter [1], but has better behavior near the edges. It also has a theoretical connection with the matting Laplacian matrix [2], so is a more generic concept than a smoothing operator and can better utilize the structures in the guidance image. Moreover, the guided filter has a fast and non-approximate linear-time algorithm, whose computational complexity is independent of the filtering kernel size. We demonstrate that the guided filter is both effective and efficient in a great variety of computer vision and computer graphics applications including noise reduction, detail smoothing/enhancement, HDR compression, image matting/feathering, haze removal, and joint upsampling."
了解更多 -
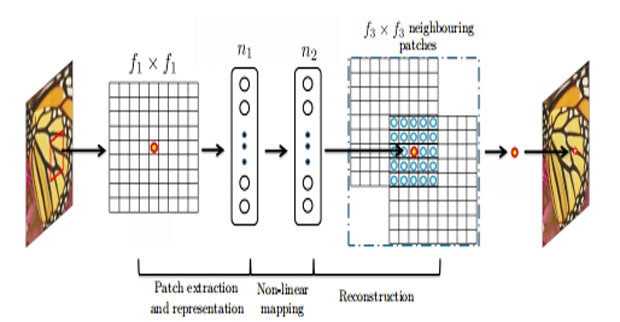 European Conference on Computer VisionLearning a Deep Convolutional Network for Image Super-Resolution
European Conference on Computer VisionLearning a Deep Convolutional Network for Image Super-Resolution时间:2014年 | 作者:Chao Dong, Chen Change Loy, Kaiming He & Xiaoou Tang
We propose a deep learning method for single image superresolution (SR). Our method directly learns an end-to-end mapping between the low/high-resolution images. The mapping is represented as a deep convolutional neural network (CNN) [15] that takes the lowresolution image as the input and outputs the high-resolution one. We further show that traditional sparse-coding-based SR methods can also be viewed as a deep convolutional network. But unlike traditional methods that handle each component separately, our method jointly optimizes all layers. Our deep CNN has a lightweight structure, yet demonstrates state-of-the-art restoration quality, and achieves fast speed for practical on-line usage.
了解更多 -
 European Conference on Computer Vision(ECCV)Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
European Conference on Computer Vision(ECCV)Temporal Segment Networks: Towards Good Practices for Deep Action Recognition时间:2016年 | 作者:Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang & Luc Van Gool
Deep convolutional networks have achieved great success for visual recognition in still images. However, for action recognition in videos, the advantage over traditional methods is not so evident. This paper aims to discover the principles to design effective ConvNet architectures for action recognition in videos and learn these models given limited training samples. Our first contribution is temporal segment network (TSN), a novel framework for video-based action recognition. which is based on the idea of long-range temporal structure modeling. It combines a sparse temporal sampling strategy and video-level supervision to enable efficient and effective learning using the whole action video. The other contribution is our study on a series of good practices in learning ConvNets on video data with the help of temporal segment network. Our approach obtains the state-the-of-art performance on the datasets of HMDB51 (69.4%) and UCF101 (94.2%). We also visualize the learned ConvNet models, which qualitatively demonstrates the effectiveness of temporal segment network and the proposed good practices. 1
了解更多

青衫磊落,格究智理,学贯中西,胸怀报国宏图志,悲憾科海巨星陨,阴阳割昏晓
丹心耿介,矢志原创,千古文章,情倾桃李满天下,惟愿此去山水寄,天地一沙鸥
遇见了你
我们才有这最好的时光

